End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for Human Pose Estimation
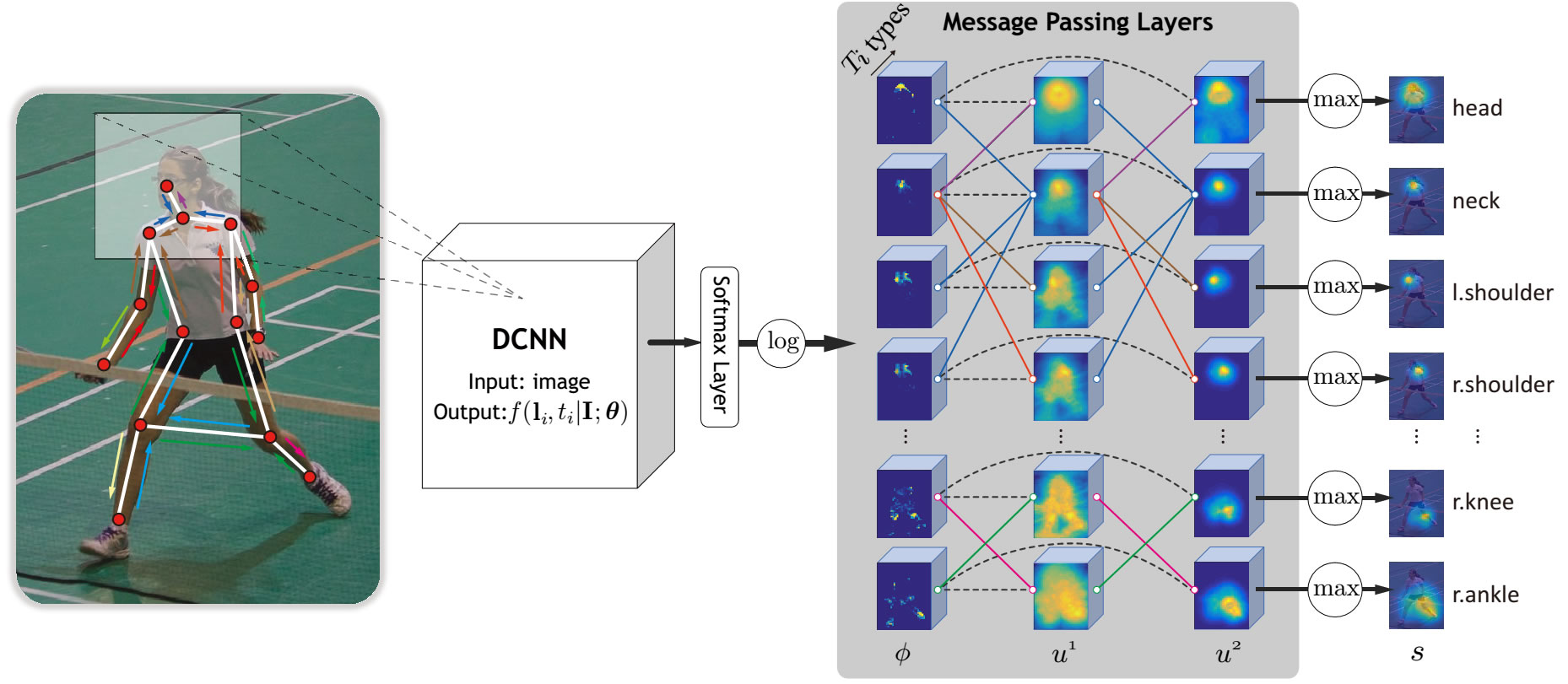
Abstract
Recently, Deep Convolutional Neural Networks (DCNNs) have been applied to the task of human pose estimation, and have shown potential of learning better feature representation and capturing contextual relationships. However, it is difficult to incorporate domain prior knowledge such as geometric relationships between body parts into DCNNs. In addition, training DCNN-based body part detectors without consideration of global body joint consistency introduces ambiguities, which increases the complexity of training.
In this paper, we propose a novel end-to-end framework for human pose estimation that combines DCNNs with the expressive deformable mixture of parts.
We explicitly incorporate domain prior knowledge into the framework, which greatly regularizes the learning process, while still keeps the flexibility of our framework to be able to handle loopy graphical models or tree-structured models.
The effectiveness of jointly learning a DCNN with a deformable part-based model is evaluated through intensive experiments on several widely used benchmarks.
The proposed approach significantly improves the performance compared with state-of-the-art approaches especially on benchmarks with challenging articulations.





Qualitative Results
 Results on LSP dataset (1st row), FLIC dataset (2nd row), and PARSE dataset (3rd row). We visualize the joint locations toghther with the graph model used in this paper (for simplicity, we only show tree-structured graph), and same limb across different images has the same color. Some failure cases are showed in the last row. Our method may lead to wrong estimations due to significant occlusions, ambiguous background, or heavily overlapping persons.
Results on LSP dataset (1st row), FLIC dataset (2nd row), and PARSE dataset (3rd row). We visualize the joint locations toghther with the graph model used in this paper (for simplicity, we only show tree-structured graph), and same limb across different images has the same color. Some failure cases are showed in the last row. Our method may lead to wrong estimations due to significant occlusions, ambiguous background, or heavily overlapping persons.
Results on a solo dance video (without temporal constraints). [Download video](http://pan.baidu.com/s/1kUWXANd)
Presentation @ Ceasars Palace, Las Vegas
Quantitative Evaluation
PCP and PDJ
Comparison of strict PCP on the Leeds Sport Pose (LSP) Dataset using Observer-Centric (OC) annotations. Note that DeepPose, CVPR’14 uses Person-Centric annotations.
| Method | Torso | Head | Upper Arms | Lower Arms | Upper Legs | Lower Legs | Mean |
|---|---|---|---|---|---|---|---|
| Yang&Ramanan, CVPR’11 | 84.1 | 77.1 | 52.5 | 35.9 | 69.5 | 65.6 | 60.8 |
| Pishchulin et al., CVPR’13 | 87.4 | 77.4 | 54.4 | 33.7 | 75.7 | 68.0 | 62.8 |
| Eichner&Ferrari, ACCV’13 | 86.2 | 80.1 | 56.5 | 37.4 | 74.3 | 69.3 | 64.3 |
| Kiefel&Gehler, ECCV’14 | 84.3 | 78.3 | 54.1 | 28.3 | 74.5 | 67.6 | 61.2 |
| Pose Machines, ECCV’14 | 88.1 | 80.4 | 62.8 | 39.5 | 79.0 | 73.6 | 67.8 |
| Ouyang et al., CVPR’14 | 88.6 | 84.3 | 61.9 | 45.4 | 77.8 | 71.9 | 68.7 |
| Pishchulin et al., ICCV’13 | 88.7 | 85.1 | 61.8 | 45.0 | 78.9 | 73.2 | 69.2 |
| DeepPose, CVPR’14 | - | - | 56 | 38 | 77 | 71 | - |
| Chen&Yuille, NIPS’14 | 92.7 | 87.8 | 69.2 | 55.4 | 82.9 | 77.0 | 75.0 |
| Ours | 96.5 | 83.1 | 78.8 | 66.7 | 88.7 | 81.7 | 81.1 |
PDJ comparison of elbows, wrists, knees and ankles on the Leeds Sport Pose (LSP) Dataset. We compare our methods with
Chen&Yuille, NIPS’14,
Ouyang et al., CVPR’14,
Ramakrishna et al., ECCV’14,
Pishchulin et al., ICCV’13 ,
and Kiefel&Gehler, ECCV’14. We report the PDJ rate at the threhold
of 0.2 in the legend (View full image).

Strict PCP results on the PARSE dataset. Note that our model is
trained on the LSP dataset to demonstrate its generalization ability.
| Method | Torso | Head | Upper Arms | Lower Arms | Upper Legs | Lower Legs | Mean |
|---|---|---|---|---|---|---|---|
| Yang&Ramanan, CVPR’11 | 82.9 | 77.6 | 55.1 | 35.4 | 69.0 | 63.9 | 60.7 |
| Johnson&Everingham, CVPR’11 | 87.6 | 76.8 | 67.3 | 45.8 | 74.7 | 67.1 | 67.4 |
| Pishchulin et al., CVPR’12 | 88.8 | 73.7 | 53.7 | 36.1 | 77.3 | 67.1 | 63.1 |
| Pishchulin et al., CVPR’13 | 92.2 | 70.7 | 54.9 | 39.8 | 74.6 | 63.7 | 62.9 |
| Pishchulin et al., ICCV’13 | 93.2 | 86.3 | 63.4 | 48.8 | 77.1 | 68.0 | 69.4 |
| Yang&Ramanan, TPAMI’13 | 85.9 | 86.8 | 63.4 | 42.7 | 74.9 | 68.3 | 67.1 |
| Ouyang et al., CVPR’14 | 89.3 | 89.3 | 67.8 | 47.8 | 78.0 | 72.0 | 71.0 |
| Ours | 97.1 | 86.8 | 80.2 | 69.3 | 84.9 | 78.5 | 81.0 |
| Method | Upper arms | Lower arms | Mean |
|---|---|---|---|
| MODEC, CVPR’13 | 84.4 | 52.1 | 68.3 |
| Tompson et al., NIPS’14 | 93.7 | 80.9 | 87.3 |
| Chen&Yuille, NIPS’14 | 97.0 | 86.8 | 91.9 |
| Ours | 98.1 | 89.5 | 93.8 |

PCK
We also report the PCK@0.2 on all the three dataset.
| Method | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean |
|---|---|---|---|---|---|---|---|---|
| LSP (OC) | 90.6 | 89.1 | 80.3 | 73.5 | 85.5 | 82.8 | 68.8 | 81.5 |
| FLIC (OC) | 98.7 | 98.6 | 96.8 | 94.2 | 79.6 | - | - | 93.6 |
| Parse (no retrain) | 88.8 | 86.6 | 79.5 | 64.4 | 76.8 | 80.0 | 62.2 | 76.9 |
(last update: June 20, 2016)